
A journey through setting up the IDIAP fork of 🐸Coqui TTS on a Windows machine
Recently I’ve been making audiobooks and wanted more control than online tools typically offer. So, I set out to train some FOSS models (Tacotron2, GlowTTS) using the IDIAP fork of Coqui TTS, with a RTX 4060.
🐸 Why the IDIAP Fork?
The official Coqui TTS repo is unmaintained as of 2024. I used the IDIAP fork:
- Better recipe support (e.g., for LJSpeech)
- Cleaner training API and updated configs
💻 System Specs
- OS: Windows 11
- GPU: NVIDIA GeForce RTX 4060 8GB
- Python: 3.12
- Shell: Git Bash (critical note below)
- PyTorch: 2.5.1 + CUDA 11.8 (must match driver/CUDA 12.6 compatibility)
🔧 Step-by-Step: Getting It to Train
1. Download LJSpeech Dataset
I manually downloaded it from keithito.com since Git Bash didn’t support wget out of the box.
2. Install the Right PyTorch + CUDA Version
Even though my system has CUDA 12.6, I had to match PyTorch with a compatible build.
3. ⚠️ Windows Multiprocessing Requires __main__
Windows doesn’t use the fork() model like Linux. So when torch.utils.data.DataLoader uses multiprocessing, you must wrap all logic like this:
if __name__ == "__main__":
trainer.fit()
4. Git Bash vs PowerShell: Setting CUDA_VISIBLE_DEVICES
In Git Bash:
CUDA_VISIBLE_DEVICES="0" python train_tacotron_dca.py
5. Run Training and Watch Logs
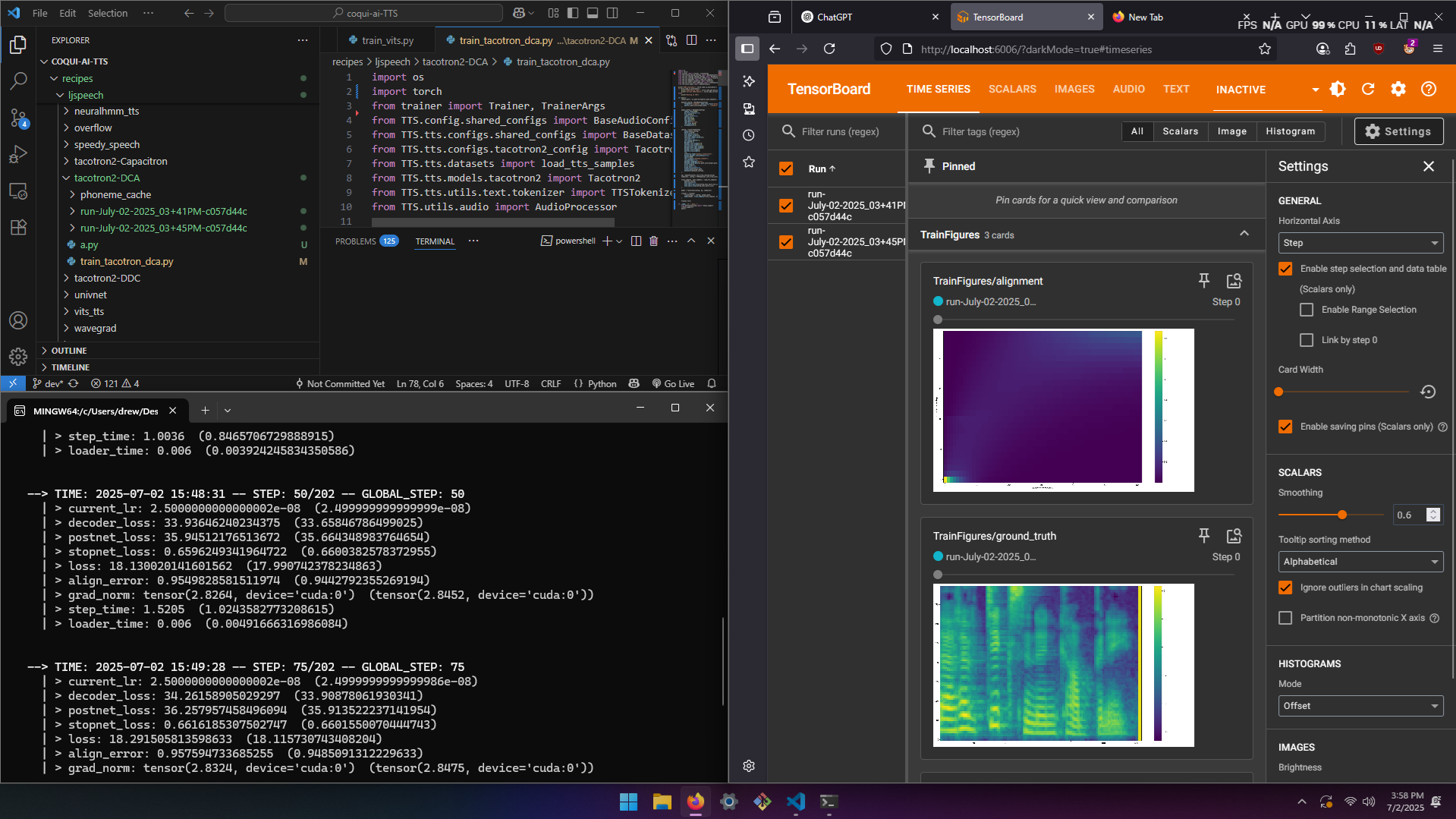
Once everything was set up, I monitored training and logs via TensorBoard: tensorboard --logdir=.
Early step loss values:
decoder_loss: 32.8
postnet_loss: 34.8
total_loss: 17.5
⚠️ Warnings I Saw (and Ignored)
Character '͡' not found in the vocabulary.→ Safe to ignore (phoneme ligatures)audio amplitude out of range, auto clipped.→ Normalization can fix it
✅ Summary: What Worked
| Component | Outcome |
|---|---|
| Git Bash | Works with CUDA — just mind how it handles env vars |
| IDIAP Fork | Clean, modular, supports Tacotron2-DCA |
| GPU (RTX 4060) | Detected and used via PyTorch |
| TensorBoard | Worked great to monitor logs |
| Training | Slow at first, but stable |
🧠 Lessons for Anyone Training on Windows
- Wrap all training logic inside
if __name__ == "__main__": - Manually download datasets if
wgetfails - Use the correct CUDA version for your PyTorch build
- If a file is “in use,” TensorBoard is likely the culprit
Results
$ tts --text "Hello, this is a test of the Tacotron2-DCA text to speech model." \
--model_path best_model_203.pth \
--config_path config.json \
--out_path output.wav
Tacotron2 Epoch ≈ steps per epoch (202) x step time (6s average) ≈ 1212s ≈ 20’/e.
July, 2 2025: The first go using the tacotron2-dca had an avg_align_error increasing past 0.96 to 0.966 over 3k+ steps, with no diagonal in attention. This means the model never learned correct alignments, so it wasn’t able to associate phonemes with the corresponding audio.
Leave a Reply