

“The best minds of my generation are thinking about how to make people click ads.”
— someone smart, probably
But what if, instead, we just built… a human? Not in the biological sense (ew, messy), but in the AI sense. Let’s go full Musk-mode and break this down from first principles1.
✅ The Goal:
Construct an intelligence system equivalent to a human brain.
Step 1 — Decompose the Human Intelligence Stack™
| Component | Human | LLM | Engineering Gap |
|---|---|---|---|
| Input | Continuous:  , ,  | Discrete:  (token sequences) (token sequences) | Add continuous sensory streams |
| Memory | Dynamical system:  | Static weights + RAG hacks | Integrate dynamic, differentiable memory |
| Agency | Utility maximizer: ![\max_{a} \mathbb{E}[U(s, a)]](https://s0.wp.com/latex.php?latex=%5Cmax_%7Ba%7D+%5Cmathbb%7BE%7D%5BU%28s%2C+a%29%5D&bg=ffffff&fg=000&s=0&c=20201002) | Zero agency; acts when called | Implement agent loop + self-initiation |
| Learning | Online updates:  | Offline SGD | Enable continual learning |
| Embodiment | Physical coupling:  | None (optional) | Hook up to sensors + actuators |
| Emotion | Internal reward function:  | Simulated patterns | Approximate intrinsic reward signals |
Step 2 — Translate into Engineering Terms
- Perception: Multimodal Transformer (image, audio, sensor → tokens)
- Memory: Differentiable Memory Modules (NTM, DNC)
- Agency: Agent loop (AutoGPT style)
- Learning: Online Gradient Descent / Reinforcement Learning
- Embodiment: Robotics + Control Theory
- Emotion: Learned utility function
Step 3 — It’s Just Math (Elon Voice)
At the end of the day, the brain is just:
A highly parallel, real-time, self-updating, multi-modal, embodied agent optimizing for survival.
And the math? Just some light bedtime reading:
![\pi: s \to a, \quad \text{maximize} \quad \mathbb{E}[U]](https://s0.wp.com/latex.php?latex=%5Cpi%3A+s+%5Cto+a%2C+%5Cquad+%5Ctext%7Bmaximize%7D+%5Cquad+%5Cmathbb%7BE%7D%5BU%5D&bg=ffffff&fg=000&s=0&c=20201002)
This is the agent’s policy function. It means that the agent (whether it’s a robot, a human, or a bored LLM pretending to be helpful) takes its current state 

![\mathbb{E}[U]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BU%5D&bg=ffffff&fg=000&s=0&c=20201002)

This is the agent’s internal reward function (or you could say “emotion function” if you’re feeling philosophical). Here, the agent looks at the current situation (state 
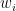
Combined, these two equations describe a simple but surprisingly deep story of intelligent behavior: decide what to do (policy) based on how you feel about the situation (emotion/reward).
Step 4 — First Principles Reality Check
Is there any magic ingredient?
- Compute
- Data
- Integration
And possibly a touch of existential dread.
Step 5 — Why Aren’t We Already There?
- It’s hard.
- It’s expensive.
- It’s easier to ship another GPT-4 powered SaaS for lawyers.
- We’re busy pitching this blog post as a seed round.
TL;DR
From first principles, building a human-level intelligence seems… annoyingly possible. Not mystical. Just systems integration at scale.
The future is going to be weird.
Next Up
how actual neuroscience models today literally describe the brain as an approximate Bayesian2, embodied, RL agent, which is just a fancy way of saying… we are surprise-avoiding computers3.
- https://en.wikipedia.org/wiki/First_principle ↩︎
- https://en.wikipedia.org/wiki/Free_energy_principle ↩︎
- Friston, K. (2010). The free-energy principle – https://www.fil.ion.ucl.ac.uk/~karl/The%20free-energy%20principle%20A%20unified%20brain%20theory.pdf ↩︎
Leave a Reply