

In AI systems, scaling models to handle high loads and provide fast responses is a complex problem.
1. Distributed Cloud Infrastructure
To handle large-scale inference, AI models are deployed on distributed cloud infrastructure. This infrastructure consists of compute nodes (virtual machines or containers), spread across multiple servers to balance the load.
Key Concept: In a distributed system, each node can process a part of the request, and these requests are processed in parallel. This reduces the time to process requests significantly. The latency LL for processing a request can be defined as:

Where:
is the number of nodes.
is the latency at each node.
By distributing tasks across multiple nodes, the total latency is reduced compared to processing requests on a single machine. This approach is widely used in cloud-based services such as Amazon Web Services (AWS)1 and Google Cloud2 for elastic scaling.
2. GPU and TPU Acceleration
AI models, particularly deep neural networks (DNNs), require massive matrix operations, which are accelerated by GPUs (Graphics Processing Units) and TPUs (Tensor Processing Units). These devices excel at parallel computation, allowing the model to process large amounts of data simultaneously.
For example, the operation at the core of most DNNs involves matrix multiplication, which is computationally expensive. If 
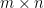

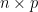

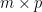

GPUs allow this operation to be performed in parallel across thousands of cores, significantly speeding up the process. TensorFlow (2015)3 and PyTorch (2016)4 are examples of popular frameworks that leverage GPUs to accelerate DNN computations.
3. Stateless Execution Model
A scalable AI system operates in a stateless manner. This means each request is processed independently, without any dependency on past requests. For each incoming request 
For instance, if an AI system needs to predict the next word in a sentence based on the context, it only processes the current input and disregards any past interactions once the response is generated. This stateless model is crucial for scaling, as it avoids session management overhead and ensures the system is ready to handle requests at any time.
The computational complexity of stateless models is 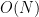
4. Load Balancing and Data Flow
To efficiently manage multiple requests and ensure no node is overwhelmed, load balancing is used. Incoming requests are distributed across available compute nodes, ensuring that each node processes an approximately equal share of the workload.
Load balancing is often achieved through round-robin or least-connections algorithms. The load 

Where:
.
By balancing the load, each node can maintain low latency and avoid being a bottleneck. Load balancing principles are central to Kubernetes orchestration5 in modern cloud-native systems.
5. Model Optimization and Frameworks
For AI models to run efficiently at scale, optimization techniques like quantization and pruning are applied. These techniques reduce the size and computational requirements of a model without significantly impacting accuracy.
Quantization reduces the precision of weights in the model from 32-bit floating-point numbers to 16-bit or 8-bit integers. This decreases memory usage and speeds up computation because fewer bits need to be processed. The number of bits

This optimization is critical when scaling up AI models, as it allows them to fit into smaller memory spaces and reduce the cost of inference. Popular frameworks like TensorFlow Lite6 and ONNX7 support these optimizations.
Pruning involves removing redundant weights from the model, making it sparser. The number of operations required for matrix multiplication decreases because fewer weights need to be processed.
6. Real-Time Monitoring and Metrics
Continuous monitoring is crucial for large-scale AI systems to ensure performance and resource utilization are optimal. Metrics like response time, resource utilization, and model accuracy are tracked.
Real-time monitoring can be modeled as a continuous function of time 

Where:
is the system metric at time
is the load at time
is the resource utilization at time
is the accuracy at time
This function ensures that any fluctuations in load, utilization, or accuracy are detected, allowing operators to take corrective action when needed.
References:
- Amazon Web Services. (2021). Scaling AI in the Cloud. Retrieved from https://aws.amazon.com/scaling-ai ↩︎
- Google Cloud. (2022). Scalable AI Inference. Retrieved from https://cloud.google.com/scalable-ai-inference ↩︎
- TensorFlow. (2015). TensorFlow: A System for Large-Scale Machine Learning. Retrieved from https://www.tensorflow.org ↩︎
- PyTorch. (2016). PyTorch: An Imperative Style, High-Performance Deep Learning Library. Retrieved from https://pytorch.org ↩︎
- Kelsey, R., et al. (2017). Kubernetes Up & Running. O’Reilly Media. ↩︎
- TensorFlow. (2021). TensorFlow Lite for Mobile Devices. Retrieved from https://www.tensorflow.org/lite ↩︎
- Microsoft. (2020). ONNX Runtime for Scalable Inference. Retrieved from https://onnxruntime.ai ↩︎
Leave a Reply