

The Transformer architecture, introduced in AIAYN1, revolutionized machine learning and natural language processing (NLP). It became the foundation for state-of-the-art models such as BERT2 and GPT3. But what exactly makes the Transformer so revolutionary? In this post, we will delve into the key innovations and how they work, with a focus on the math behind them.
1. Limitations of Previous Models
Before the advent of Transformers, models like RNNs4 (Recurrent Neural Networks) and LSTMs (Long Short-Term Memory networks) processed information sequentially. This meant that the hidden state 

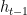

Where:
is the weight matrix for the hidden state.
is the weight matrix for the input
at time
is a non-linear activation function (or
sigmoid).
While effective for short sequences, this process struggled with long-range dependencies due to the vanishing gradient problem. Sequential processing also slowed down training since each word depended on processing the previous word.
2. Self-Attention: A Game-Changer
The breakthrough of the Transformer architecture lies in self-attention. In self-attention, instead of processing words one by one, the model considers all words in the input sequence at once. Each word attends to every other word in the sentence to understand context, using attention scores.
The attention mechanism computes a weighted sum of values 



Where:
is the value matrix.
is the dimension of the key/query vectors.
- The softmax function normalizes the attention scores.
This allows the model to weigh the importance of different words. For example, in the sentence, “The cat sat on the mat, and it was happy,” the model can understand that the word “it” refers to “cat” by assigning a higher attention score between these two words.
3. Parallelization for Faster Training
One of the major advantages of the Transformer over previous architectures is its ability to parallelize computations. Since each word attends to every other word at once (using self-attention), the model can process all words simultaneously rather than sequentially.
This results in significantly faster training because the model doesn’t need to wait for previous words to be processed before moving on to the next. In mathematical terms, the self-attention mechanism computes all pairwise relationships between words in parallel, which can be efficiently implemented using matrix multiplications.
4. Positional Encoding
Since Transformers do not process sequences in order, they need a way to represent the position of words in a sentence. This is done through positional encodings. The positional encoding for each word at position 
The positional encoding formula is as follows:


Where:
represents the position in the word embedding.
is the dimension of the word embeddings.
These sine and cosine functions encode positions in a way that allows the model to learn patterns of relationships between words in a sequence, even though it processes them all in parallel.
5. Scalability and Pretraining
The self-attention mechanism is also highly scalable. It allows for deeper models with more layers and can handle larger datasets. By pretraining large models on vast amounts of text data, researchers can create general-purpose language models like BERT and GPT-3 that are fine-tuned on specific tasks, such as sentiment analysis or machine translation.
These pre-trained models leverage the power of large-scale attention mechanisms to improve their performance. The output of the self-attention mechanism can be fed into a stack of feedforward layers, making it easier for the model to learn complex patterns in the data.
Conclusion
The Transformer architecture has transformed machine learning, primarily through the use of self-attention and the ability to parallelize computations. This revolutionary approach overcame the limitations of sequential models like RNNs and LSTMs, enabling the model to capture long-range dependencies and scale efficiently. With its flexibility, the Transformer architecture now underpins many of the most advanced AI models used today in NLP, computer vision, and beyond.
Leave a Reply